
概要
プログラミング言語にあらかじめ用意されている変数の型を組込み型といいます。 ここでは、C# の組み込み型について説明します。
ポイント
-
整数(int)や文字列(string)などは、C# 言語に組み込まれた型です
-
整数、浮動小数点数、文字、文字列、10進小数、論理値
C# の型
C# の型は、以下のように分類されます。
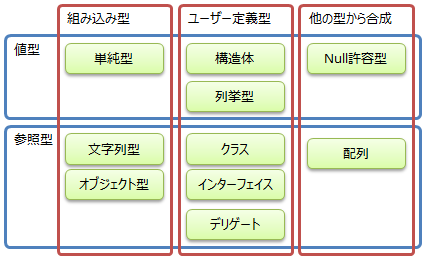
このうち、本項で説明するのは「組み込み型」のところになります。
他に関しては後々説明していきます。
-
列挙型:「列挙型」
-
インターフェイス:「インターフェース」
-
デリゲート:「デリゲート」
-
Null 許容型:「Nullable 型」
-
配列:「配列」
組込み型の種類
C# には以下のような組込み型が用意されています。
| 符号付き | 符号無し | |||
|---|---|---|---|---|
| 単純型 | 整数型 | 8ビット整数 |
sbyte
|
byte
|
| 16ビット整数 |
short
|
ushort
|
||
| 32ビット整数 |
int
|
uint
|
||
| 64ビット整数 |
long
|
ulong
|
||
| 文字型 | char | |||
| 浮動小数点型 | 単精度 |
float
|
||
| 倍精度 |
double
|
|||
| デシマル(10進小数) |
decimal
|
|||
| 論理値型 |
bool
|
|||
| 文字列型 |
string
|
|||
| オブジェクト型 |
object
|
|||
※ C# 9.0 以降はこれに加えて、サイズが環境によって変わる nint、nuint という型もあります。
リテラル
int x = 10; というように書くとき、10 のような値をそのまま書いた部分のことをリテラル(literal: 「文字通りの」という意味。見たまんまの定数)と呼びます。
組み込み型には、型ごとにリテラルの書き方があります。
ちなみに、リテラルのことは「定数」とは訳しません。 通常、「定数」は constant の訳語です(参考: 「定数」)。 literal を和訳する場合には、直定数と訳されます。
整数型
数学では無限の桁数の数字を扱えますが、コンピュータの内部では値を記憶しておく場所が限られているため、扱える値の範囲も限られています。 当然、桁の大きな値ほど大きな記憶領域を必要とします。 また、符号の有無によっても扱える値の範囲は変わります。
以下にC#の整数型の一覧を挙げます。
| 型名 | 記憶領域サイズ | 符合の有無 | 扱える値の範囲 |
|---|---|---|---|
byte
|
1バイト | なし | 0 ~ 255 |
sbyte
|
1バイト | あり | -128 ~ 127 |
short
|
2バイト | あり | -32,768 ~ 32,767 |
ushort
|
2バイト | なし | 0 ~ 65,535 |
int
|
4バイト | あり | -2,147,483,648 ~ 2,147,483,647 |
uint
|
4バイト | なし | 0 ~ 4,294,967,295 |
long
|
8バイト | あり | -9,223,372,036,854,775,808 ~ 9,223,372,036,854,775,807 |
ulong
|
8バイト | なし | 0 ~ 18,446,744,073,709,551,615 |
int は integer (整数)の略で、short と long の意味は名前通り、記憶領域サイズの長い/短いの違いです。
byte も名前通りで「1バイトの変数」という意味です。
sbyte の「s」は signed の s で符号付きを意味します。
また、uint, ushort, ulong の「u」は unsigned の u で符号無しを意味します。
ちなみに、8バイトよりも大きな整数値を扱いたい場合、BigInteger構造体(System.Numerics名前空間)という物を使います。
(構造体や名前空間については別項にて説明します。)
また、C# 9.0 で追加された nint、nuint は、
32ビット CPU で使う場合は int、uint と同じで、
64ビット CPU で使う場合は long、ulong と同じ範囲の値を使えます。
ただし、どちらのタイプの CPU で実行するかは事前にはわからないので、
ソースコード中に書けるリテラルとしては32ビット分(int、uint と同じ)しか使えません。
整数リテラル
C# のソースコード中に直接整数値を書き込むと整数リテラルとみなされます。
また、整数値の後ろに「u」か「U」を付けると符号なし整数とみなされ、
「l」か「L」を付けると long 型のリテラルとみなされます。
int k = 351; // 整数リテラル
uint l = 86U; // 符号なし
long m = 1879L; // Lを付けるとlongとみなされる
ulong n = 2419UL; // UとLを付けるとulongとみなされる
文字型
コンピュータは基本的に数値しか扱えません。 そのため、文字もコンピュータの内部では整数値として扱われています。 どの文字に対して何番の数字を割り当てるかは、標準化団体によって取り決めがなされています。 このような取り決めによって文字に割り当てられた整数値を文字コードといいます。
C# では、内部的に Unicode という2バイトの文字コードが使われています。 (正確には UCS-2。サロゲートなしの UTF-16。 残念ながら、UTF-32 ではないので、一部の文字(サロゲート ペア)の表現に2文字分の領域を使います。)
とにかく、C# の文字型
char
(characterの略)は2バイトの数値として扱われます。
文字リテラル
文字リテラルは
'a'
といったように ' (シングルクォーテーション)で囲んで表現します。
前述の通り、C# の char型 UTF-16 なので、文字リテラルも2バイトの数値です。
short や ushortとは、互いに桁落ちなく変換することもできます。
short x = (short)'a'; // 97 と同じ意味
char c = (char)97; // 'a' と同じ意味
また、' 自身を表す文字リテラルは
'\''
というように書きます。
char c = 'a'; // 文字リテラル
エスケープ シーケンス
C# では \ 記号(バックスラッシュ。日本語環境だと ¥ マークで表示されることもあり)が特別な意味を持っていて、\ に続く数文字を一定のルールで別の文字に置き換えます。
以下のような用途で使います。
''中で'自体を書くなど、本来書けない場所に記号を書く- 改行文字やタブ文字など、不可視だけどそれなりの頻度で使いたい文字を目に見える形で書く
(今となってはほとんど使わないような文字も、古くからの名残で数文字あります。 通信で文字くらいしか送れなかった時代の名残であったり、 文字ではないもののキーボードにボタンがあるものであったりです。)
この \ 記号から始まる特殊記法を、
「書けない文字を書くための回避策(escape)」、「数文字(sequence)使って1文字を表す」という意味で、エスケープ シーケンス(escape sequence)と言います。
C# は以下のようなエスケープ シーケンスを持っています。
| 使う文字 | 意味 | Unicode の値(16進数) |
|---|---|---|
\' |
' (引用符)。文字リテラル('') 中に ' を書くために使う |
27 |
\" |
" (2重引用符)。文字列リテラル("") 中に " を書くために使う |
22 |
\\ |
\ (バックスラッシュ)。エスケープ シーケンスにでない意味で \ を書くために使う |
5C |
\0 |
null 文字(文字列の終端を表したり、特別な使い方をする文字) | 00 |
\a |
アラート音(ビープ音を鳴らすのに使ってた) | 07 |
\b |
バックスペース(1文字前文字を消す) | 08 |
\f |
フォーム フィード(タイプライターで用紙送りに使ってたコード) | 0C |
\n |
改行(new line) | 0A |
\r |
復帰(carriage return)。行頭に戻る処理※ | 0D |
\t |
水平タブ | 09 |
\v |
垂直タブ | 0B |
\e |
【C# 13 以降】エスケープ文字 | 1B |
\u |
Unicode の値直打ち(4桁) | 後述 |
\U |
Unicode の値直打ち(8桁) | 後述 |
\x |
Unicode の値直打ち(任意桁) | 後述 |
※Windows で改行が \r\n なのは、行頭に戻る + 次行に移る の組み合わせが必要だった時代の名残り。今となっては \n だけで改行を表せるので \r は 微妙な文字。
\u、\U、\x は実際には \u0061、\U0001F60A、 \x61 などというように、後ろに16進数の値を伴います。
この、後ろに書かれた16進数の数値を文字コードに持つ文字に置き換わります。
例えば16進数で61というのはアルファベットの a を表すコードで、要するに \u0061 は a と同じ意味になります。
Console.WriteLine('\u0061'); // 文字 a
Console.WriteLine("\U0001F60A"); // 絵文字の 😊
Console.WriteLine('\x61'); // 文字 a。4桁固定じゃないということ以外は \u と同じ
\u、\U、\xの3つの差は、後ろに続く16進数の長さの差です。
\u… 4桁固定。61であっても\u0061というように0を埋めて4桁にする必要がある\U… 8桁固定。同様に0埋めして8桁にする必要がある\x… 任意桁
前述の通り、C# の文字は UTF-16 になっていて2バイトの数値です。
これは Unicode が2バイト固定だった(65536文字ですべての文字を表せるとおごっていた)時代の名残で、今となっては char では表せない文字がたくさんあります。
(日本の常用漢字が2136文字ですし、1990年代以前には文字は2バイトもあれば十分だと思われていました。)
\U (16進数8桁 = 4バイト)はそういう2バイトに収まらない文字を表すのに使います。
例えば絵文字がそうで、😊 の文字コードは 1F60A なので、C# では \U0001F60A と書くことができます。
char では値が収まらないので、文字リテラル('')中には書けません。
後述する文字列リテラルの中で使います。
(無意味ですが、0で埋めてわざわざ \U00000061 などと書くなら、char として有効な値なので文字リテラルの中にも書けます。)
\x は、後ろに続く16進数が任意桁である点だけが \u との差です。
任意桁数な代わりに、区切りがはっきりしている場面でしか使えません。
例えば、\u0061b (文字コード 61 の後ろに文字 b)なら ab と同じ意味なりますが、
\x61bと書いてしまうとこれは文字コード 61B (アラビア語の文字です)の意味になります。
ちなみに、\u と \U は文字・文字列リテラルの外で、識別子にも使えます。
var \u0061 = 1; // var a = 1; と同じ意味
Console.WriteLine(a); // 1
Console.WriteLine(\U00000061); // 記法が違ってもやっぱり a の意味で解釈されるので 1 が表示される
Console.WriteLine(nameof(\u0061)); // a と表示される
浮動小数点型(実数型)
整数型のところでも述べたように、コンピュータの中では有限桁の数しか扱えませんので、 厳密にはコンピュータの中で「実数型」というものは扱うことが出来ません。 しかし、科学技術計算などでは、非常に大きな数や、非常に小さな数を扱いたい場面がしばしばあります。
そこで、「1.4982654×1058」というように、 指数表記を使って数を表すことを考えます。 こうすることで、非常に大きな数や、非常に小さな数を限られた桁数で表現することが出来ます。 小数点の位置を変えて数を表現するので、このような形式の数を浮動小数点数(floating point number)といいます。 コンピュータの内部では、実数はこのように浮動小数点数として(近似的に)扱われています。
以下にC#の浮動小数点型の一覧を挙げます。
| 型名 | 記憶領域サイズ | 精度 | 扱える値の範囲 |
|---|---|---|---|
float
|
4バイト | 7桁 | ±1.5 × 10-45~ ±3.4 × 1038 |
double
|
8バイト | 15桁 | ±5.0 × 10-324~ ±1.7 × 10308 |
floatは floating-point (浮動小数点)の略で、doubleは double-precision floating-point (倍精度浮動小数点)という意味です。
ちなみに、浮動小数点数の内部的な形式(何ビット目がどういう意味を持つか)は標準規格化されていて、 ほとんどの CPU やプログラミング言語では IEEE 754 という名前の規格を使っています。
浮動小数点リテラル
C# のソースコード中に小数を書き込むと浮動小数点リテラルとみなされます。
数値の後ろに「f」か「F」を付けると float 型とみなされ、
「d」か「D」を付けると double 型とみなされ、
また、浮動小数点リテラルは指数表記(2.56×104といった形式。2.56の部分を仮数部、10の肩に乗っている4のことを指数部といいます)でも書くことが出来ます。
指数表記のリテラルの書き方は [仮数部]e[指数部] (例えば、2.56×104は2.56e4と書く)です。
double x = 2.2362; // 浮動小数点リテラル
float y = 2.7183f; // fを付けると単精度
double z = 6.02e23; // 指数表記 6.02×10^23
デシマル(10進小数)
float や double などの浮動小数点数は、コンピュータの内部では2進小数になっています。 表1に、2進小数と10進小数の対応関係の例をいくつか挙げます。
| 2進小数 | 10進小数 |
|---|---|
| 0.1 | 0.5 |
| 0.01 | 0.25 |
| 0.11 | 0.75 |
| 0.001 | 0.125 |
| 0.000110011… | 0.1 |
これで何が問題になるかというと、 実は、(10進数での)0.1 すら、浮動小数点数では正確に(有限桁で)表すことができません。
元々誤差がつき物な科学技術計算などではこれが問題になることもないんですが、 例えば、金融などの分野では、「1.1ドル(1ドル10セント)」が正確に表せないとなると大問題になります。
そこで、C# では10進小数を表すための decimal という型が用意されています。
decimal m = 99.9m; // mを付けるとdecimalになる
一見、浮動小数点と似ていますが(小数点の位置が動くという意味では decimal も浮動小数点なんですが)、 float、double と比べて以下のような特徴があります。
-
内部的に10進数になっているので、0.1m と書けば正確に 0.1 になる。
-
floatやdoubleと比べて、精度が高い代わりに、表現できる数の範囲が狭い(つまり、指数部の桁が少ない) -
サイズが16バイトと、他の数値型と比べて大きい。
表現できる数の範囲を以下に示します(比較のため、改めて浮動小数点数の値の範囲も示します)。
| 型名 | 記憶領域サイズ | 精度 | 扱える値の範囲 |
|---|---|---|---|
float
|
4バイト | 7桁 | ±1.5 × 10-45~ ±3.4 × 1038 |
double
|
8バイト | 15桁 | ±5.0 × 10-324~ ±1.7 × 10308 |
decimal
|
16バイト | 28桁 | 1.0 × 10-28~ 7.9 × 1028 |
double 型と比べて、大きな数を表すことは出来ない代わりに、表現できる桁数が多くなっています。
そのため、float や double とはまったくの別物として扱われ、
互いに暗黙的な型変換ができなくなっています。
2008年に IEEE 754 規格が更新されて、10進小数にも標準規格ができました。 しかし、C# の誕生よりも後なため、C# の decimal 型の内部表現はこの IEEE 754-2008 規格と互換性がありません。
デシマルリテラル
小数の後ろに「m」か「M」を付けると decimal 型とみなされます。
decimal m = 99.9m; // mを付けるとdecimalになる
論理値型
論理値とは条件式が正しいか間違っているかをあらわすものです。 正しい状態(真または true という)と、 間違った状態(偽または false という)の2つの値を持ちます。
C# では論理値型は
bool
(boolean の略。論理代数を考案した George Bool という人物にちなんで論理値のことを英語で boolean という)といいます。
論理値リテラル
論理値リテラルは真を表す
true
と、
偽を表す
false
の2つです。
bool b = x==1; // x が 1 ならば true 、そうでなければ false になる。
bool t = true; // 直接 true を代入
bool f = false; // 直接 false を代入
ちなみに、1行目を見ての通り、== などの比較演算の結果は bool 値になります。
文字列型
文字列は名前通り、文字の列なわけですから、
char
型の配列で十分な気もします。
実際、C言語などのプログラミング言語では文字列は char 型の配列として扱われています。
しかし、文字列には、連結、検索、置換、数値への変換など、文字の配列には無い機能が必要になります。
そのため、C# では
string
という文字列用の型が用意されています。
文字列リテラル
文字列リテラルは
"文字列の例"
といったように " (ダブルクォーテーション)で囲んで表現します。
また、文字列リテラル中で " を使うためには、
文字リテラル中の'と同様にエスケープシーケンスを使って
"<a href=\"index.html\">"
というように表現します。
string s = "C#入門"; // 文字列リテラル
string x = "\uff9f\u0434\uff9f"; // Unicodeを直入力。 ゚д゚ ←これ。
逐語的文字列リテラル
※ C# 11 からは「生文字列]」という同用途の別構文があります。こちらの方が書きこごちがよかったりするので、こちらの記事もご確認ください。
文字列リテラルの書き方にはもう1種類あって、@"@-quoted string" というように、
'' や "" の前に @ (アットマーク)を付けると \ とそれに続く文字がエスケープシーケンスとはみなされず、
普通に \ 記号として解釈されます。これを逐語的文字列リテラル(verbatim string literal)といいます。
string path = @"C:\windows\system"; // 逐語的リテラル(@-quoted string)。 \ 記号がそのまま解釈される。
ちなみに、逐語的文字列リテラルの場合、複数行に渡る文章を書くことも出来ます。 改行の位置にはちゃんと改行文字が入ります。
string multiLineString =
@"@-quoted string では、
文章を複数行に渡って書くことができます。
";
Console.Write(multiLineString);
こういう逐語的文字列リテラルの使い方のことを here 文字列と言ったりもします。 (エスケープなし、改行も含めて全部見たまま「ここに書いた通り」という意味。)
また、逐語的文字列リテラル中で " (ダブルクォーテーション)を使いたい場合は、"" というように、2つ並べて書きます。
var s = @"
var s = ""here 文字列中の引用符"";
";
Console.WriteLine(s);
var s = "here 文字列中の引用符";
特殊な文字列
Ver. 6
C# 6 で、文字列関連の機能が増えました。 詳しくは、「特殊な文字列リテラル」 で説明します。
オブジェクト型
object はオブジェクト型と呼ばれ、任意の型の値を格納できる型です。
C# では、組込み型・ユーザー定義型を問わずすべての型は object から派生しています。
(ユーザー定義型や派生については後ほど説明します。)
null
string 型や object 型は、有効な値の他に、無効な(まだ初期化されていない)状態を表す null という値を持つことができます。
object notInitializedVariable = null;
null (無効な値)を代入できるのは、参照型か Nullable 型のみになります (参考: 「値型と参照型」、「Nullable 型」)。
.NET の型
.NET では、組み込み型を可能な限り他の型(詳細は後述)と区別しないようにしています。 int のような組み込み型も、「.NET の標準ライブラリ中の型の1つ」に見えるように作られています。
ということで、C# の組込み型も、実際には、.NET の標準ライブラリで定義されている型の別称になっています。 (頻繁に使うので、C# の予約語として省略形を提供している。) 以下に、C# の組込み型名と .NET の標準ライブラリで定義されている型との対応表を示します。
| C# | .NET 標準ライブラリ |
|---|---|
bool
|
System.Boolean
|
byte
|
System.Byte
|
sbyte
|
System.SByte
|
short
|
System.Int16
|
ushort
|
System.UInt16
|
int
|
System.Int32
|
uint
|
System.UInt32
|
long
|
System.Int64
|
ulong
|
System.UInt64
|
nint
|
System.IntPtr
|
nuint
|
System.UIntPtr
|
char
|
System.Char
|
float
|
System.Single
|
double
|
System.Double
|
decimal
|
System.Decimal
|
string
|
System.String
|
object
|
System.Object
|
特別扱いを受けないという意味では、「C# には組み込み型はない」とも言えるでしょう。 ただし、実際のところ、ここで紹介したような「組み込み型」は、コンパイルの挙動的には結構特別扱いされています。
既定値
C# では、変数を明示的に初期化しなかった場合に与えられる、既定値(default value)というものが決まってます。 (Main メソッドなどの内部で使う変数(=ローカル変数と言います)の場合は、必ず明示的な初期化が必要です。 一方で、今後説明していくような、クラスのフィールドや、配列の要素では、明示的に初期値を与えず、既定値で初期化することができます。)
既定値は、現時点では 0 (数値の場合)もしくは null (string や object の場合)とだけ覚えておいてください。
既定値を得るための default 式というものもあります。例えば、以下のように書くと、int の規定値(0)が得られます。
int n = default(int);