
概要
Ver. 3.0
C# 3.0 では、var キーワードを用いて、暗黙的に型付けされたローカル変数を定義できるようになりました(型推論(type inference))。 型推論は便利な機能ではあるんですが、“いいことずくめ”なものではなく、少々副作用もあって、 その利用形態をめぐって軽い論争が起きたりもしています。
具体的にいうと、var の利用ポリシーとして、 以下のようなものが考えらていて、 どれがいいのかでもめています。
-
匿名型利用時など、どうしても必要なときだけ使う
-
↑に加え、右辺が new SomeClass() のようなときだけ var を使う
-
int, string などの組み込み型に対しては使わない
-
使えるところでは全部使う
“いいことずくめ”なんだったら「使えるところでは全部使う」でいいんですが、 最初に言ったように、少々副作用を伴うので、利用を制限した方がいいのではないかという話。 実際、マイクロソフト自身も、MSDN Library などのドキュメント中では「型推論がどうしても必要な場合に限って var を使う」という方針を採っています。
現状(2010年)の認識
ほとんどの場合は var を使って問題ないはずです。 var を使って見づらいと感じる場合、それは var 自体の問題というよりは、他の要因(1つのメソッドが長すぎるなど)があるので、リファクタリングしましょう。
ただし、var の見やすさは Visual Studio などの IDE 前提な面があります。 そのため、教科書や、MSDN Library などのドキュメント上では var が避けられる傾向があります。
最初に私見を
最初に私見を書いておこうかと。
まず何より、「C# 3.0 の var はあくまで「型推論」であって、バリアント型ではない」ということは改めて念を押しておきます。型が合ってなければコンパイル時にエラーがでるし、Visual Studio で変数にマウスカーソルを合わせれば型名が表示される。C# が型の甘い言語になったということでは断じてない。
で、var 利用ポリシーに関して、僕としては、当初は、
-
型は厳格であって欲しい
-
冗長な記述も、人的エラーのコンパイル時訂正機能として働く
という理由から var は乱用すべきではないなぁと思っていたんですが。
最近はどうかというと、特にこだわることなく適当にコードを書いていて、ふと自分のコードを見返してみると「var が使えるところでは割と全部 var」になっていて、しかもそれで可読性が落ちたとも感じませんでした。多分、Visual Studio の補助があるからこそそう感じるんだと思いますが。まあ、せいぜい、右辺値からぱっと見で型がよっぽど想像しにくそうなときにだけ var を避けようかなぁと思うくらい。
var の長短
var、すなわち、型推論の導入というのは、結局のところ、コードの冗長性の排除なわけですね。
SomeClass x = new SomeClass();
みたいなコード、なんで2度も SomeClass って書かなきゃいけないのよと。以下のように、型名が長い場合には特にうんざりします。
System.Collections.Generic.List<int> list =
new System.Collections.Generic.List<int>();
プログラミングの格言の1つに、Don't Repeat Yourself、通称“DRY 原則”というのがあって、重複・冗長性は排除しろといわれます。重複があると、何か変更する際に複数の場所を書き換えないと動かない。手間はかかるし、バグの原因になるからやめろと。
一方で、冗長性というのはエラー耐性を生む場合もあります。通信・符号化理論を学んだことがある人は分かると思いますが、日常的にやり取りしている情報には冗長性があって、それを排除することでファイルサイズを圧縮したり、逆に、ファイルサイズを増やす代わりにエラー訂正・検出能力を持たせることができます。
冗長性によるエラー耐性 例えば以下のコードを考えてみます。
int n1 = 10; // (1)
var n2 = 10; // (2)
(1) の場合、左辺値だけで型は明らかに int だと分かります。一方、(2) の場合は、「サフィックスなしの数値リテラルは int だよな」と一瞬考えて初めて int 型だと分かります。もちろん、C# になれた人からするとこのくらいは常識ではあるんですが、チーム開発とかやると、自分が常識だと思っていることで、チームメイトとの意思疎通に失敗することもあるので危険だと。結局、冗長なままにしておいた方が読みやすくていいだろうって話に。
あと、以下のようなコードも考えてみましょう。
var x = 1;
var y = .1;
たった1つの . の有無で変数の型が変わります。まあ、等幅フォントを使っていて . が見えないってことはないし、ちゃんと 0.1 と書けよという話ではあるんですが。でも、冗長性を極力排除するというのは、こういう「コード上ほんの少しの変更が、コンパイル結果に大きな変化をもたらす」という状況を生みます。これは、時に、重大なエラーを引き起こす可能性を秘めています。
DRY 原則
ところで、最初のコード、開発の途中で「整数にするよりも浮動小数点にする方がよさそうだぞ」と思ってしまった場合にはどうなるでしょう。
// (1)
// int n1 = 10;
// ↓
double n1 = 3.14;
// (2)
// var n2 = 10;
// ↓
var n2 = 3.14;
(1) の側は左右両辺書き換えが必要になりますね。ここだけではなく、n1 を利用する箇所全部で修正が必要になるかもしれません。ところが、(2) の側はその必要がない。これが、最初に言った DRY 原則って奴です。冗長なコードを書くと、仕様変更時に修正が複数個所に及び、手間がかかると。
ある意味、var は Generics と一緒で、静的ポリモーフィズムに使えるわけです。どんな型にでも対応可能な変数が作れるけども、コンパイル時には型が確定します。
作法の問題?
「変数の型が右辺値を見て明らかな場合にのみ var を使う」と決めた場合、以下のようなコードはどう考えるべきでしょう。
var x = GetPoint();
SetPoint(x);
メソッドの名前からして Point 型だろうとは想像付きますが、それは System.Drawing.Point 型?それとも、自作の Point 構造体?
また、前節の説明どおり、var は静的ポリモーフィズムの1形態とも考えられるんで、型が分かることが必ずしもいいとは限らないわけです。
例えば、↑のコードは SetPoint(GetPoint()); とほぼ同様のコードとみなせます。この場合、GetPoint() の戻り値が System.Drawing.Point だろうが、System.Windows.Media.Media3D.Point3D だろうが、自作の Point 構造体だろうが、なんだってかまわない。要は、GetPoint の戻り値と SetPoint の引数の型があってさえすればそれで OK。ところが、変数 x の型を明示してしまうとそうも言っていられないと。
で、じゃあ、今度は以下のようなコードを考えてみましょう。
var x = GetPoint();
// 長い処理
SetPoint(x);
最初のコードには賛成派な人も、こうなると一気に否定的印象を持つんじゃないでしょうか。最初のコードは、変数 x のスコープが短いんで、「ぱっと見で型が判別しづらい」という var の欠点があまり問題にならないんですが、間に長い処理が挟まることで、その欠点が問題になりそうだと、警戒感が生まれます。
でも、このコード、変数名に x なんていう適当な名前をつけてるのがそもそもの問題とも取れます。
プログラミング作法的には、一般に、処理の単位ごとに細かく関数に区切るべきだとされていますし、変数名も意味のある名前をつけろってのが常識。そうすると、↑みたいなコードの問題は、結局、var が悪いんじゃなくて、長ったらしい関数を書いたこととか x っていう適当な名前を付けたことにあるのかもしれない。
同じようなものでも、以下のようなコードならどうでしょうか。
var point = GetPoint();
// 長いっていってもせいぜい1画面に収まる程度の処理
SetPoint(point);
ずいぶんと印象が変わると思います。
結局、コードの可読性というのは、var の是非の問題というか、プログラミング作法の問題な気がします。
Visual Studio による補助
var を使うと変数の型が分かりにくくなるというのも、var の方がタイピング数が少なくていいというのも、Visual Studio を使ってプログラミングをしているとどちらも大した問題にはならなかったり。もちろん、全ての人が Visual Studio を使ってるわけではないですし、中にはやっぱり、テキストエディタでプログラミングをしたいという昔かたぎな人もいるわけですけど。
まあ、例えば、以下のコードを Visual Studio で打つことを考えます。
DateTime d1 = new DateTime(); // (1)
var d2 = new DateTime(); // (2)
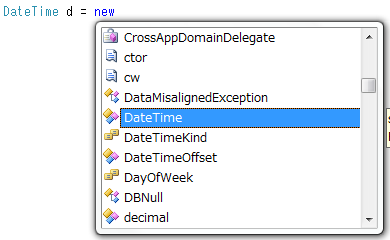
まず、タイピング数に関しては、(1) の方は「DateTime d = new 」まで打てばインテリセンスで DateTime が出てくる(図1)のに対して、(2) の方は new の後ろをちゃんと打たないといけません。結局、インテリセンスに頼る限り、タイピング数に大差は生まれません。
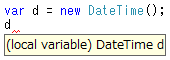
変数 d の型の判別のしやすさも、型を明記しようが var を使おうが、Visual Studio で変数 d にマウスカーソルを合わせれば型名が出てくるんで(図2)、型を明記するメリットはあんまり大きくもないです。
[余談] ラムダ式と var の相性の悪さ
少し話題はそれますが、var による型推論は、ラムダ式と相性が悪かったりします。
(追記: ラムダ式以外にも、同様に var と相性の悪い構文がいくつかあります)
例えば、以下のコードはコンパイルができますが、
Func<int, int> f1 = x => x * x;
var f2 = (Func<int, int>)(x => x * x);
以下のコードはコンパイルできません。
var g1 = x => x * x;
var g2 = (int x) => (int)(x * x);
var g3 = (Func<int, int>)x => x * x;
(追記: C# 10.0 からは g2 についてはコンパイルできるようになっています。
詳しくは「デリゲートの自然な型」で説明します。)
g1 がコンパイルできない理由は簡単。ラムダ式は左辺を見て型推論して、var は右辺値を見て型推論する。循環していては型推論ができるはずはないと。
g2 は、C# では同じシグネチャを持つ別のデリゲートを定義できるのが原因で、int → int のメソッドなことが分かっていても、デリゲートの型が確定しない。
g3 は単純ミスですね。ラムダ式を作るための => 演算子よりも、キャスト演算子の方が結合順位が高いせいです。(Func<int, int>)(x => x * x) と書けばコンパイルできます。
ラムダ式に対して無理やりにでも var を使いたければ、例えば、以下のような補助メソッドを書いて、
static Func<T, T> F<T>(Func<T, T> func)
{
return func;
}
以下のようにします。
var f3 = F<int>(x => x * x);
var f4 = F((int x) => x * x);
この場合でも、以下のようなコードはコンパイルできません。
var g4 = F(x => (int)x * x);
Func<int, int> g5 = F(x => x * x);
Generics も型推論に頼っているので、変にサボろうとするとうまく型推論が働かなくなります。