
型スイッチ(switch を使ったパターン マッチング)の用途
型によって分岐する方法としては、仮想メソッドを使う方法があります。 オブジェクト指向プログラミング言語としては、仮想メソッドが相当に便利で、実行性能もよく、こちらが好まれます。 極端な意見では、「型を調べたら負け」、「ダウンキャストが必要なのは筋が悪い」という人すらいます。
ここでは、この仮想メソッドと、本稿の主題である型スイッチの使い分けについて説明します。
例として、以下のようなクラス階層を考えます。
public abstract class Node { }
public class Var : Node { }
public class Const : Node
{
public int Value { get; }
public Const(int value) { Value = value; }
}
public class Add : Node
{
public Node Left { get; }
public Node Right { get; }
public Add(Node left, Node right)
{
Left = left;
Right = right;
}
}
public class Mul : Node
{
public Node Left { get; }
public Node Right { get; }
public Mul(Node left, Node right)
{
Left = left;
Right = right;
}
}
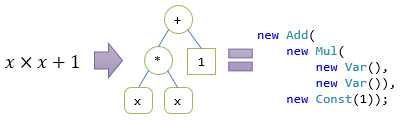
説明都合で簡素化していますが、数式を扱うようなクラスです。 要するに、例えば、「」というような式を、以下のようなコードで表すためのクラスです。
var expression = new Add(
new Mul(
new Var(),
new Var()),
new Const(1));
これに対して、「変数の値を与えて、式の計算結果を得る」というようなメソッドを、仮想メソッドと型スイッチの両方で作ってみましょう。
まず、仮想メソッドなら以下のようになるでしょう(必要な部分だけを抜き出してあります)。
abstract class Node
{
public abstract int Calculate(int x);
}
class Var
{
public override int Calculate(int x) => x;
}
class Const
{
public override int Calculate(int x) => Value;
}
class Add
{
public override int Calculate(int x) => Left.Calculate(x) + Right.Calculate(x);
}
class Mul
{
public override int Calculate(int x) => Left.Calculate(x) * Right.Calculate(x);
}
一方、型スイッチを使って書くなら以下のようになります。
public static class NodeExtensions
{
public static int Calculate(this Node n, int x)
{
switch (n)
{
case Var v: return x;
case Const c: return c.Value;
case Add a: return Calculate(a.Left, x) + Calculate(a.Right, x);
case Mul m: return Calculate(m.Left, x) * Calculate(m.Right, x);
}
throw new ArgumentOutOfRangeException();
}
}
それぞれ、以下のような特徴があります。
-
性能:
- 〇 仮想メソッドはかなり実行性能がいい
- × 型スイッチでは性能面はかなわない
-
実装の強制
- 〇 仮想メソッドなら、抽象メソッドにしておけば派生クラスでの実装漏れがあり得なくなる
- × 型スイッチの場合、
caseへの追加忘れがあり得る
-
実装を書ける場所
- × 仮想メソッドはクラスの中にないとダメ
- 〇 型スイッチなら拡張メソッドなど、クラスの外でも使える
基本的にはやっぱり仮想メソッドの方が性能・使い勝手の面で良かったりします。 ただ、仮想メソッド最大の問題は、クラスの中に書くのが必須ということです。 どうしてもクラスの中には書けない(クラスの作者自身が書けず、第三者が書く必要がある)場合というのはあって、 この場合は型スイッチを使う必要があります。
クラスの中に書くということは、そのクラスを使いたい人なら誰でも使うような汎用的な機能なはずです。 仮想メソッドはそういう汎用的な機能にしか使えないということになります。
一方で、使う人それぞれの固有の事情であれば、使う人の側が自分で書くことになるでしょう。
例えば、表示要件を考えてみます。
あるアプリでは、「x * x + 1」というように、プログラミング言語によくあるように、掛け算を*で表して文字列化したいかもしれません。
またあるアプリでは、「」というように、ちゃんと数式フォントで、掛け算には×記号を使って表示したいかもしれません。
数式表示のためには、自前でレンダリングを行うべきかもしれませんし、
「<math><mi>x</mi><mo>×</mo><mi>x</mi><mo>+</mo><mn>1</mn></math>」というようなMathML文字列を作って、これを何らかのライブラリに解釈してもらうのがいいかもしれません。
数式データを使う用途もアプリごとに変わってくるでしょう。 あるアプリでは、数式を組版して表示すること自体が目的かもしれません。 またあるアプリでは、数式を微分したり方程式の解を求めたり、数学計算のために使うかもしれません。 あるいは、プログラミング言語を作っていて、式を計算するCPU命令を出力するための中間形式として使うかもしれません。
こういう、クラス作者側では用途が見えないものは、型スイッチを使って書くことになります。
補足: 型スイッチの性能
仮想メソッドと比べると遅いという話をしましたが、これは、仮想メソッドが性能よすぎるだけで、
型スイッチもそこまでひどい性能ではありません。
先ほどのCalculateの例でいうと、大まかに計測したところ4倍程度の差でした。
「型を見る」というと、リフレクションを想像する人がいるようです。 リフレクションを使う場合、確かに、2・3桁(2・3倍じゃなくて、桁が変わる)遅くなる場合があります。 しかし、型スイッチに必要なのは「その型に代入できるかどうか」だけで、これはそこそこ高速な処理です。 リフレクションで遅いのは、「ある型がどういうメンバーを持っているか調べる」であるとか、 「メソッド名を文字列で渡してメソッドを探して、そのメソッドを実行する」であるとかです。
要するに、リフレクションで取れる型情報や、それの使い方には何段階かあって、それぞれ負荷の度合いも変わります。
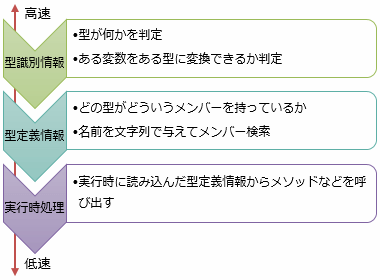
型識別だけなら大したコストは掛かりません。そして、型スイッチが使うのはこの型識別情報だけです。
むしろ、型スイッチの遅さの原因は、
前項で説明したような、逐次判定のせいです。
上から1つ1つcaseの条件判定しているので、平均的にはcaseの数に比例した処理量が必要になります。